
1. 재해 발생 시 인프라 보호
재해 발생 시 인프라를 보호할 수 있는 몇 가지 방법은 다음과 같습니다.
- 여러 AWS 스토리지 서비스를 사용하여 데이터 복제
- 빠르게 배포 가능한 AMI를 생성하여 컴퓨팅 리소스 시작
- 장애가 발생한 구성요소에서 다른 구성요소로 트래픽을 라우팅하는 여러 장애 조치 메커니즘을 사용하여 네트워크 설계
- 데이터베이스 스냅샷 및 백업 사용
재해 복구 계획의 구성 요소:
| 테스트 | 구현 검증 |
| 리소스 | 복구 경로를 프로덕션 환경에서 정기적으로 실행 |
| 계획 | 복구 패턴을 설정하고 정기적으로 테스트 |
가용성 개념:
| 고가용성 | - 가동 중단 시간 및 비용을 최소화 - 장애로부터 보호 - 매우 짧은 가동 중단, 신속한 복구, 낮은 비용으로 비즈니스를 지속 운영 가능 |
| 내결함성 | - 서비스 중단이 발생하지 않도록 애플리케이션 구성요소에 내장된 중복성 - 비용 많이 발생 |
| 백업 | 데이터 보호 및 비즈니스 연속성 보장 |
| 재해복구 | 데이터 손실 없이 신속하게 서비스를 복원 |
RPO(복구시점목표) 및 RTO(복구시간목표):
| 복구 시점 목표(RPO) | 복구 시간 목표(RTO) |
| 시간 단위로 측정한 허용 가능한 데이터 손실량 | 중단 후 복원하기까지 걸리는 시간 |
| 데이터 손실 최소화 | 가동 중단 시간 최소화 |
| 데이터를 백업해야 하는 빈도 | 애플리케이션을 사용할 수 없어도 되는 시간 |
일반적으로 회사는 시스템을 가동할 수 없을 때 기업에 미칠 재정적 영향에 근거하여 허용 가능한 RPO 및 RTO를 결정합니다.
회사는 가동 중단 시간 및 시스템 가용성 부족으로 인한 사업 손실 및 회사 평판 손상 등 여러 가지 요인들을 고려하여 재정적 영향을 평가합니다.
IT 조직은 RTO에 따라 수립된 일정 및 서비스 수준의 범위 내에서 RPO에 근거하여 비용 효율적인 시스템 복구를 제공할 수 있는 솔루션을 계획합니다.
재해 복구 AWS 서비스 및 기능:
| 스토리지 복제 | Amazon S3 | 다른 AWS 리전에 있는 여러 버킷에서 객체를복사 |
| Amazon S3 Glacier | - 데이터가 리전 저장소에 저장 - 매일 인벤토리가 업데이트됨 - 자주 액세스하지 않는 데이터에 최적화 |
|
| Amazon EBS | - 특정 시점 볼륨 스냅샷 생성 - 리전 및 계정 간에 스냅샷 복사 |
|
| AWS Snow Family | - 고객과 AWS 간의 대규모 데이터 전송 - 물리적 전송 시 보안을 유지하도록 설계됨 - 고속 인터넷보다 빠르게 Amazon S3에 저장된 데이터 복원 가능 |
|
| AWS DataSync | 온프레미스 또는 클라우드 파일 시스템의 파일을 Amazon EFS와 동기화 | |
| 복구용 AMI 구성 | 새로운 서버 인스턴스 또는 컨테이너를 몇 분 만에 확보하고 부팅 | |
| 네트워크 설계 | Route 53 | - 트래픽 분산 및 장애 조치 - 정적 웹사이트 간에 장애 조치를 실행하는 DNS 엔드포인트 상태 확인을 다룰 때 효과적 |
| ELB | - 로드 밸런싱, 상태 확인 및 장애 조치 - 수신되는 애플리케이션 트래픽에 응답하는데 필요한 로드밸런싱 용량을 제공해 내결함성 보장 - 로드밸런서를 사전 구성하여 해당 DNS 이름을 식별하고 재해 복구 계획을 실행 |
|
| Amazon VPC | - 기존 네트워크 토폴로지를 클라우드로 확장 - 내부 네트워크에 위치한 엔터프라이즈 애플리케이션을 복구에 적합 |
|
| Direct Connect | - 온프레미스 환경에서 AWS로의 전용 네트워크 연결을 설정 - 네트워크 비용을 감소 - 대역폭 처리량 상승 - 인터넷 기반 연결보다 더 일관된 네트워크 환경을 제공 |
|
| 데이터베이스 백업 및 복제본 |
Amazon RDS | - 데이터 스냅샷을 생성해 별도의 리전에 저장 - Multi-AZ 클러스터 배포를 활용해 대기 인스턴스와 읽기 전용 복제본을 사용 - 자동 백업을 보존 |
| DynamoDB | - 전체 테이블을 몇 초 안에 백업 - 특정 시점으로 복구를 사용하여 최대 35일 동안 지속적으로 테이블을 백업 - 글로벌 테이블을 사용해 전 세계에 분산된 앱의 로컬 성능을 개선 - 글로벌 테이블의 모든 복제본을 단일 단위로 처리 |
|
| AWS CloudFormation |
템플릿 | 필요에 따라 리소스 모음을 신속하게 배포 |
| 스크립트 | 클라우드에서 인프라 프로비저닝을 자동화 | |
2. 백업 전략 자동화
AWS Backup은 완전 관리형 백업 서비스로, AWS 서비스 전체에 걸쳐 데이터 백업을 중앙 집중화하고 자동화할 수 있습니다.

AWS Backup은 AWS Organizations와 연동합니다.
중앙에서 데이터 보호 정책을 배포하여 백업 활동을 구성, 관리 및 제어할 수 있습니다.
AWS Backup은 Amazon EC2 인스턴스와 Amazon EBS 볼륨을 비롯한 여러 AWS 계정과 리소스에서 작동합니다. DynamoDB 테이블, Amazon DocumentDB 및 Amazon Neptune 그래프 데이터베이스, Amazon RDS 데이터베이스(Amazon Aurora 데이터베이스 클러스터 포함) 등의 데이터베이스를 백업할 수 있습니다.
그리고 Amazon EFS, Amazon S3, AWS Storage Gateway 볼륨 및 모든 Amazon FSx 버전(FSx for Lustre 및 FSx for Windows File Server 포함)도 백업할 수 있습니다.
AWS Backup 이점:
| 간편성 | - 정책 기반 및 태그 기반 백업 - 자동화된 백업 일정 관리 |
| 규정 준수 | - 중앙 집중식 백업 활동 모니터링 및 로그 - 백업 액세스 정책 - 암호화된 백업 |
| 비용 제어 | - 가동 중지 발생 위험 감소 - 자동화된 백업 보존 관리 - 오케스트레이션 비용 추가 없음 |
AWS Backup 이점:
1. AWS Backup 계획 생성
| 일정 | 백업 빈도와 백업을 수행할 기간을 설정 |
| 수명주기 | 백업을 콜드 스토리지로 이동할 시기와 백업 만료 시기를 결정 |
| 저장소 | - 백업 계획에서 사용할 백업 저장소를 지정 - 백업 저장소를 생성할 때는 자체 암호화 방법이 없는 백업을 암호화하기 위해 AWS KMS) 암호화키를 배정 |
| 백업용 태그 | 이 계획을 통해 생성되는 백업에 배정할 태그를 지정 |
2. 백업할 리소스 할당
| 태그 | 태그가 지정된 모든 AWS 리소스는 이 계획을 통해 백업 |
| 리소스 ID | 특정 DynamoDB 테이블이나 Amazon EBS 볼륨 등의 특정 리소스에서 사용 |
3. 백업 관리 및 모니터링
Amazon CloudWatch, Amazon EventBridge, AWS CloudTrail, Amazon Simple Notification Service(Amazon SNS) 등의 다른 AWS 서비스를 사용하여 워크 로드를 모니터링합니다.
3. 가동 중단 시간 최소화
AWS 기반 재해 복구(DR) 아키텍처, 1부: 클라우드에서의 재해 복구 전략 | Amazon Web Services
이 글은 AWS Architecture Blog에 게시된 Disaster Recovery (DR) Architecture on AWS, Part I: Strategies for Recovery in the Cloud을 한국어로 번역 및 편집하였습니다. 필자는 AWS Well-Architected 신뢰성 원칙의 수석 솔루션 설
aws.amazon.com

백업 및 복원, 파일럿 라이트, AWS의 저용량 대기, 다중 사이트 액티브/액티브 재해 복구(DR) 솔루션 중에서 선택할 수 있습니다.
백업 및 복원:

Amazon S3는 백업에 빠르게 액세스할 수 있는 이상적인 대상 위치입니다.
Amazon S3와 데이터를 주고받는 과정은 주로 네트워크를 통해 이루어지므로 어떤 위치에서든 액세스가 가능합니다.
또한 수명주기 정책을 사용하여 오래된 백업을 더 비용 효율적인 스토리지 클래스로 순차 이동할 수 있습니다.
예를 들어 수명주기 정책은 버킷에 일정 시간 동안 보관되어 있었던 각 백업을 S3 Standard-IA로 이동하고, 그 후에는 백업이 Amazon S3 Glacier로 이동될 수 있습니다.
원격 서버에서 장애가 발생하면 재해복구 VPC를 배포하여 서비스를 복원할 수 있습니다.
CloudFormation을 사용해 주요 네트워킹 배포를 자동화합니다.
원격 서버와 일치하는 AMI를 사용하여 EC2 인스턴스를 생성합니다.
그런 다음 Amazon S3에서 백업을 검색하여 시스템을 복원합니다.
그 후에는 AWS를 가리키도록 DNS 레코드를 조정합니다
파일럿 라이트:
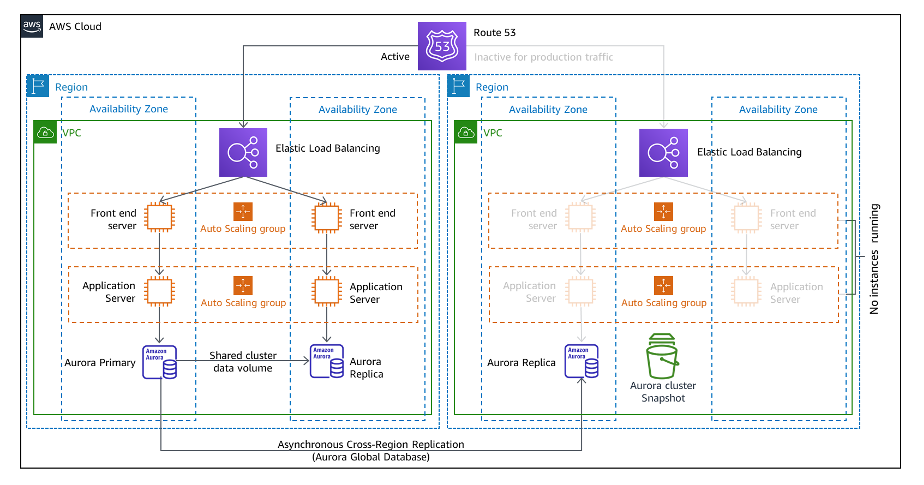
파일럿 라이트 접근 방식에서는 환경 간에 데이터를 복제하고 핵심 워크 로드 인프라의 복사본을 프로비저닝합니다.
복제된 핵심 데이터세트 주위로 리소스를 준비합니다.
필요에 따라 크기 조정하여 현재 프로덕션 트래픽을 처리합니다.
AWS를 가리키도록 DNS 레코드를 조정하여 새 시스템으로 전환합니다.
데이터 복제 및 백업을 지원하는 데 필요한 리소스(예: 데이터베이스, 객체 스토리지)는 상시 작동하고 있습니다.
애플리케이션 서버 등의 기타 요소는 애플리케이션 코드와 구성을 통해 로드되지만 꺼져있으며, 재해복구 장애 조치 호출 시나 테스트 중에만 사용됩니다.
복구 환경의 서버가 시작되면 Route 53가 프로덕션 트래픽을 복구 환경으로 전송합니다.
파일럿 라이트 아키텍처는 비교적 저렴하게 구현할 수 있습니다.
웜 스탠바이:

웜 스탠바이 방식에서는 정상작동하는 축소된 프로덕션 환경 사본을 복구 환경에 생성합니다.
AWS 상에 시스템을 모두 복제하고 상시 접속되도록 하여 복구 환경의 리소스가 시작될 때까지 기다리지 않아도 되므로 복구 시간이 단축됩니다.
이 예에서는 웹서버와 앱 서버를 Auto Scaling 그룹으로 복구 환경에 복제합니다.
Auto Scaling 그룹은 실행 가능한 최소 수의 인스턴스와 가장 작은 EC2 인스턴스 크기를 실행할 수 있습니다.
이 솔루션은 최대 프로덕션 로드를 처리할 정도로 크기가 조정되지는 않지만 기능은 온전하게 작동합니다.
Route 53를 사용해 프로덕션 환경과 복구 환경 간에 요청을 분산합니다.
그런 다음 복구 환경에 데이터베이스를 복사하고 데이터 복제를 사용하여 해당 데이터베이스를 최신 상태로 유지합니다.
프로덕션 환경을 사용할 수 없으면 Route 53는 복구 환경으로 전환합니다.
프라이머리 시스템에서 장애가 발생하면 복구 환경은 자동으로 용량을 확장합니다.
중요한 로드의 웜 스탠바이 RTO는 장애 조치 소요 시간입니다.
나머지 로드의 경우 RTO는 스케일업에 걸리는 시간입니다.
RPO는 복제 유형에 따라달라집니다.
가동 중단을 방지하는 저비용 옵션입니다.
다중 사이트 액티브/액티브:

액티브-액티브 구성에서는 다중 사이트 설루션이 2개 환경에서 실행됩니다.
Route 53는 두 환경 간에 트래픽을 라우팅합니다.
이 아키텍처는 잠재적으로 가동 중단 시간이 가장 짧지만 더 많은 환경이 실행되므로 비용도 더 많이 듭니다.
Route 53와 같은 가중치 기반 라우팅을 지원하는 DNS 서비스를 사용하면 프로덕션 트래픽을 동일한 애플리케이션이나 서비스를 제공하는 다른 사이트로 라우팅할 수 있습니다.
프로덕션 A 환경에서 재해가 발생하면 DNS 가중치를 조정하여 프로덕션 B 환경으로 모든 트래픽을 전송할 수 있습니다.
최대 프로덕션 로드를 처리할 수 있도록 AWS 서비스 용량을 신속하게 증가시킬 수 있습니다.
Amazon EC2 Auto Scaling을 사용하면 이 프로세스를 자동으로 실행할 수 있습니다.
프라이머리 데이터베이스 서비스의 장애를 감지하고 AWS에서 실행되는 병렬 데이터 베이스 서비스로 이관되기 위해 몇 가 지 애플리케이션 로직이 필요할 수 있습니다.
재해 복구(DR) 사례 비교:
| 백업 및 복원 | 파일럿 라이트 | 웜 스탠바이 | 다중 사이트 액티브/액티브 | |
| RPO/RTO | 몇 시간 | 몇십 분 | 몇 분 | 실시간 |
| 비용 | 낮음 | 조금 낮음 | 조금 높음 | 높음 |
| 우선순위 | 낮음 | 조금 낮음 | 조금 높음 | 높음 |
| 기타 | 솔루션: Amazon S3, Storage Gateway | 재해 복구 이벤트에 대한 응답으로 AWS 리소스 스케일링 | 비즈니스 크리티컬 서비스 | AWS의 환경을 실행중인 복제본으로 자동 장애 조치 |
Architecting on AWS 7.4.6 (KO): Student Guide 참고
'AWS > AWS Architecting' 카테고리의 다른 글
| [AWS Architecting]엣지 서비스 (0) | 2023.07.08 |
|---|---|
| [AWS Architecting]서버리스 (0) | 2023.07.05 |
| [AWS Architecting]자동화 (0) | 2023.07.02 |
| [AWS Architecting]모니터링 및 크기 조정 (0) | 2023.07.02 |
| [AWS Architecting]데이터베이스 (1) | 2023.07.01 |