
1. AWS 데이터베이스 솔루션
AWS는 관계형 데이터베이스 및 비관계형 데이터베이스를 지원하는 서비스를 제공합니다.
| 관계형 데이터베이스 | 비관계형 데이터베이스 | |
| 데이터 저장 | 행과 열로 이뤄진 테이블 | 키 값, 와이드 컬럼, 그래프, 문서 등 |
| 스키마 | 고정 | 동적 |
| 선택 | 엄격한 스키마 규칙 및 데이터 품질 적용이 필요한 경우 | 데이터베이스 크기를 수평으로 조정해야 하는경우 |
| 과도한 읽기/쓰기 용량은 필요치 않은 경우 | 데이터가 기존 스키마에 적합하지 않은 경우 | |
| 최상의 성능을 필요로 하지 않는 관계형 데이터 | 빠른 읽기/쓰기 속도가 필요한 경우 |
데이터베이스 유형:

2. 효율적인 관계형 데이터베이스 관리 방법
Amazon RDS와 Amazon Aurora를 사용하면 관계형 데이터베이스를 효율적으로 관리할 수 있습니다.

Amazon RDS는 획일적인 데이터베이스 관리 업무를 수행할 필요가 없는 관리형 데이터베이스입니다.
Amazon RDS 기능:
- 하드웨어, OS 및 데이터베이스 소프트웨어 배포 및 유지관리
- 기본 제공 모니터링
- 저장 데이터 및 전송 데이터 암호화
- 업계 규정 준수
- 자동 다중 AZ 데이터 복제
- 컴퓨팅 및 스토리지 크기 조정
- 최소한의 애플리케이션 가동 중단
Amazon RDS 다중 AZ 배포 및 장애조치:

- 다른 가용영역의 대기 DB 인스턴스에 데이터를 동기식으로 복제
- 읽기 전용(Read Replicas)에서는 사용되지 않음
- primay 인스턴스에 장애가 발생한 경우 대기 인스턴스로 자동 장애 조치를 수행
1. secondary 데이터베이스를 primary로 승격
2. secondary 데이터베이스가 primary 데이터베이스 엔드포인트로 전환
3. EC2 인스턴스가 새 primary 데이터베이스를 사용하여 트래픽 전송 재시작
4. 그와 동시에 새 대기 데이터베이스가 다른 가용 영역에 생성
Amazon RDS 읽기 전용 복제본(Read Replicas):
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_ReadRepl.html#USER_ReadRepl.PostgreSQL
Working with DB instance read replicas - Amazon Relational Database Service
Within an AWS Region, we strongly recommend that you create all read replicas in the same virtual private cloud (VPC) based on Amazon VPC as the source DB instance. If you create a read replica in a different VPC from the source DB instance, classless inte
docs.aws.amazon.com
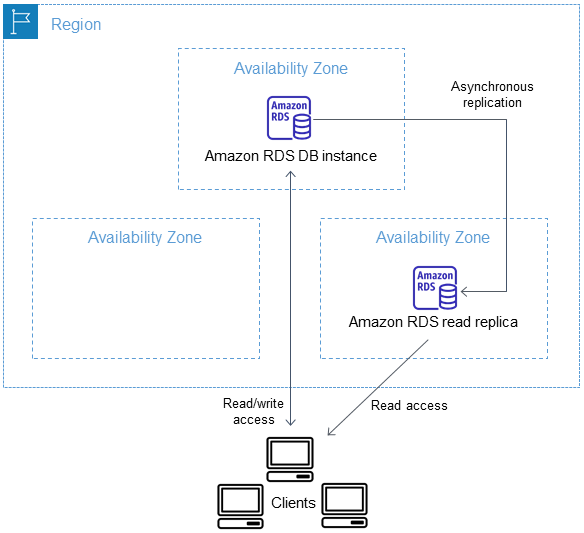
- primary 노드에 대한 부하 해소
- 다른 리전에 배치하여 애플리케이션 간 거리 축소
- primary DB 인스턴스에 장애 발생 시 재해 복구(DR) 솔루션으로 읽기 전용 복제본을 독립 실행형 인스턴스로 승격 가능
Amazon RDS 데이터 암호화:
Amazon RDS는 AWS Key Management Service(AWS KMS)를 사용하여 저장 데이터를 암호화 합니다.
AWS KMS는 암호화 키를 생성 및 관리하고 해당 키를 사용하여 데이터를 암호화 및 복호화 하는 기능을 제공하는 관리형 서비스입니다.
모든 키는 사용자의 AWS 계정에 연결되고 사용자가 관리합니다.
AWS KMS는 Amazon RDS 인스턴스의 기본 스토리지에 대한 무단 액세스로부터 보호하는 추가 보호계층을 제공합니다.
AWS KMS는 업계 표준 AES-256 암호화를 사용하여 Amazon RDS 인스턴스가 실행되는 기본 호스트에 저장되는 데이터를 보호합니다.
Amazon Aurora:
Amazon Aurora는 MySQL 및 PostgreSQL과 호환되는 완전 관리형 관계형 데이터베이스입니다.
Aurora는 데이터베이스 리소스의 안정성 및 가용성을 유지하면서 불필요한 I/O 작업을 줄여 데이터베이스 비용을 절감하는 데 도움이 됩니다.
Aurora는 6개의 데이터 복사본을 3개의 가용 영역에 복제하고 지속적으로 Amazon S3에 데이터를 백업합니다.
Aurora DB 클러스터:
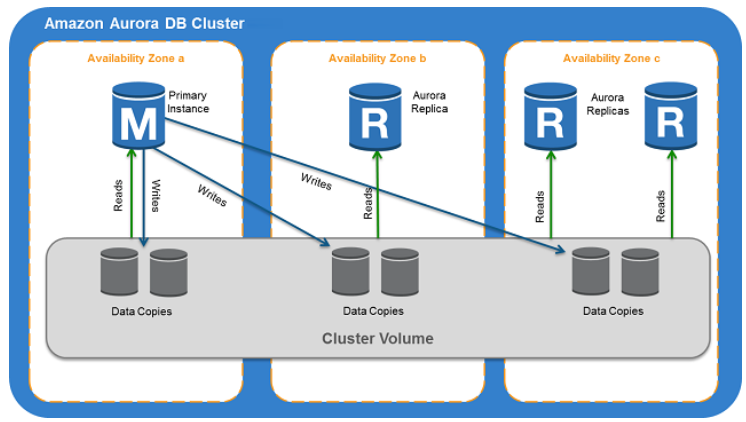
Amazon Aurora DB 클러스터는 하나 이상의 DB 인스턴스와 해당 DB 인스턴스에 대한 데이터를 관리하는 클러스터 볼륨으로 구성됩니다.
이러한 인스턴스는 데이터베이스의 컴퓨팅 기능을 수행하며, 실제 데이터는 클러스터 볼륨에 저장됩니다.
Aurora 인스턴스 유형:
| Primary 인스턴스 | - 읽기 및 쓰기 작업 지원 - 클러스터 볼륨의 모든 데이터 변경을 실행 - 각 Aurora DB 클러스터마다 프라이머리 인스턴스가 하나씩 존재 |
| Aurora 복제본 | - 읽기 작업만 지원 - 각 Aurora DB 클러스터마다 최대 15개의 Aurora 복제본이 읽기 워크 로드를 분산 - 별도의 가용 영역에 배치하여 가용성 상승 - primary 인스턴스와 동일한 리전에 있을 수 있음 |
Aurora 클러스터 볼륨:
Aurora 클러스터 볼륨은 여러 가용 영역에 걸쳐있는 가상 데이터베이스 스토리지 볼륨입니다.
각 가용 영역에는 DB 클러스터 데이터의 복사본이 있습니다.
클러스터 볼륨의 스토리지는 스토리지 노드 수백 개에 복제됩니다.
Aurora에서 클러스터 볼륨은 DB 클러스터의 Aurora 복제본과 primary 인스턴스의 단일 논리 볼륨으로 제공됩니다.
클러스터 볼륨에서 쓰기 작업을 수행하면 대개 100밀리 초 이내에 Aurora 복제본에서 해당 내용을 확인할 수 있습니다.
Amazon Aurora Serverless:
Amazon Aurora Serverless는 Aurora의 온디맨드 자동 크기 조정 구성 버전입니다.
워크 로드를 모니터링하고 애플리케이션 수요에 따라 자동으로 데이터베이스 용량을 조정합니다.
표준 MySQL 데이터베이스보다 최대 5배 빠르고 표준 PostgreSQL 데이터베이스보다는 최대 3배 빠릅니다.
3. 확장 가능한 키-값 NoSQL 데이터베이스 구축
Amazon DynamoDB를 사용하면 비관계형 키값 데이터베이스를 관리할 수 있습니다.
분산 데이터베이스를 운영하고 확장하는 데 따른 관리가 필요 없는 완전관리형 서비스입니다.
DynamoDB 키 값 데이터:
- 필요한 데이터를 기본 키에 매핑할 수 있는 상황에 사용하면 적합함
- 키 값으로 빠른 데이터 검색 가능
- 키를 기준으로 데이터분할
- 높은 처리량, 짧은 지연시간의 읽기 및 쓰기 가능
- 큰 데이터 볼륨, 짧은 지연시간, 유연한 데이터모델이 필요한 애플리케이션에 최적화
DynamoDB 테이블:
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/HowItWorks.CoreComponents.html
Core components of Amazon DynamoDB - Amazon DynamoDB
Core components of Amazon DynamoDB In DynamoDB, tables, items, and attributes are the core components that you work with. A table is a collection of items, and each item is a collection of attributes. DynamoDB uses primary keys to uniquely identify each it
docs.aws.amazon.com
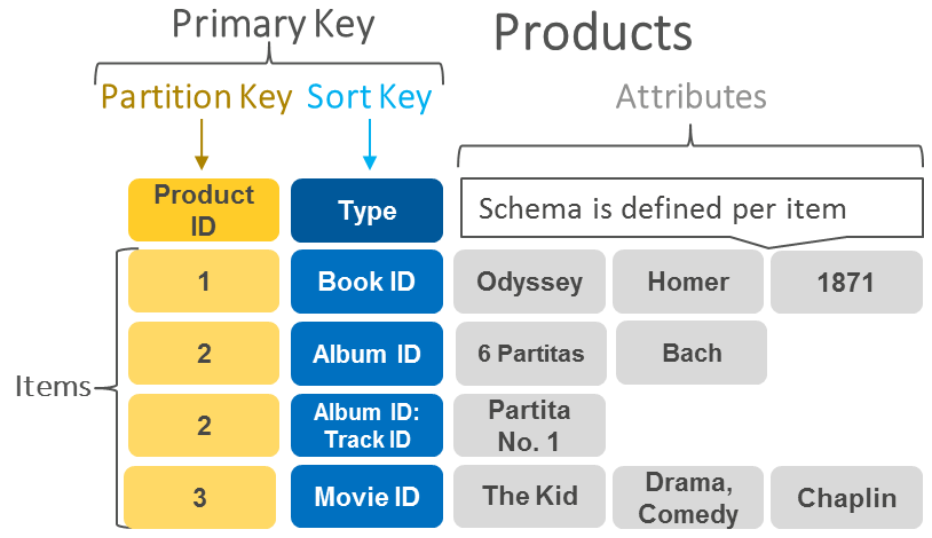
DynamoDB는 데이터를 테이블에 저장합니다.
DynamoDB는 기본 키로 각 항목을 고유하게 식별하고, 보조 인덱스로 쿼리를 작성합니다.
기본 키 유형:
| 단순 기본 키 | - 파티션 키로만 구성된 단순한 기본 키 - 파티션 키를 하나만 사용하는 경우 두 항목이 동일한 값을 가질 수 없음 |
| 복합 기본기 | - 파티션 키와 정렬 키로 구성 - 여러 항목의 파티션 키 값은 같을 수 있지만 정렬 키 값은 달라야 함 |
DynamoDB 용량 관리:
읽기 용량 단위(RCU)로 읽기 용량을 측정하고, 쓰기 용량 단위(WCU)로 쓰기 용량을 측정합니다.
초당 읽기/쓰기 요청의 예상수와 해당 요청의 크기를 고려해서 테이블용 용량 모드를 선택합니다.
| 온디맨드 모드 | - 요청 단위로 요금 부과 - 다음과 같은 상황 사용: - 워크 로드를 알 수 없는 경우 - 트래픽을 예측할 수 없는 경우 - 사용한 만큼만 지불하는 요금제를 사용하려는 경우 |
| 프로비저닝 모드 | - RCU와 WCU의 최대 수를 설정하여 한도를 초과하면 자동 크기 조정 - 다음과 같은 상황 사용: - 애플리케이션 트래픽이 예측 가능한 경우 - 트래픽의 양이 일정하거나 점진적으로 변경되는 경우 - 용량 요구사항을 예측할 수 있는 경우 |
DynamoDB 일관성:
DynamoDB는 일반적으로 1초 이내에 모든 스토리지 위치에서 최종적으로 일관된 읽기와 강력한 일관된 읽기를 지원합니다.
달리 지정하지 않은 한 DynamoDB는 최종적으로 일관된 읽기를 사용합니다.
| 최종적으로 일관된 읽기 | - 읽기 용량 단위 0.5 사용 - 최근 완료된 쓰기 작업의 결과를 반영하지 않을 수 있음 - 응답에는 부실 데이터가 일부 포함될 수 있음 - 잠시 후 읽기 요청을 반복하면 응답이 최신 데이터를 반환 |
| 강력한 읽기 일관성 | - 읽기 용량 단위 1 사용 - 가장 최신 데이터로 응답 반환 - 네트워크 지연 또는 중단이 발생하는 경우에 사용이 어려움 |
DynamoDB 글로벌 테이블:
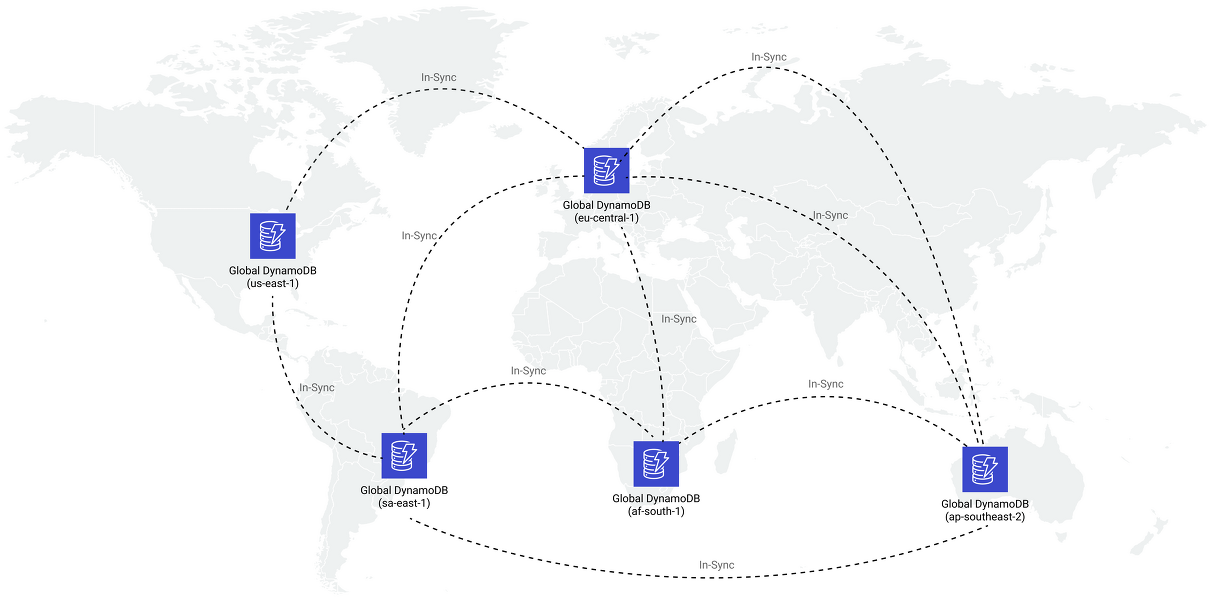
글로벌 테이블은 단일 AWS 계정이 소유하는 한 개 이상의 DynamoDB 테이블의 모음입니다.
글로벌 테이블은 리전 간 복제를 자동화합니다.
글로벌 테이블은 리전당 한 개의 복제 테이블을 가질 수 있습니다
복제 테이블(또는 줄여서 복제본)은 글로벌 테이블의 일부로 기능하는 단일 DynamoDB 테이블입니다.
각 복제본에는 동일한 데이터 항목 집합이 저장됩니다.
모든 복제본은 동일한 테이블 이름과 동일한 기본 키 스키마를 갖습니다.
4. 성능을 높이기 위한 데이터베이스 캐시
Amazon ElastiCache 및 Amazon DynamoDB Accelerator를 데이터베이스 캐싱에 사용할 수 있습니다.
캐싱을 사용하지 않는 경우 EC2 인스턴스가 데이터베이스에서 직접 읽고 씁니다.
반면 캐싱을 사용하는 경우 인스턴스는 먼저 캐시에서 읽기를 시도하는데, 이 읽기에는 고성능 메모리가 사용됩니다.
캐시해야 하는 항목:
- 쿼리 속도가 느리고 비용이 많이 드는 데이터
- 자주 액세스하는 데이터
- 비교적 정적 상태로 유지되는 정보
캐싱 전략:
Caching patterns - Database Caching Strategies Using Redis
Caching patterns When you are caching data from your database, there are caching patterns for Redis and Memcached that you can implement, including proactive and reactive approaches. The patterns you choose to implement should be directly related to your c
docs.aws.amazon.com
1. Lazy Loading(지연 로딩)
- 캐시를 업데이트하지 않고 데이터베이스를 업데이트
- 캐시 미스의 경우 데이터베이스에서 검색된 정보가 나중에 캐시에 기록될 수 있음
- 지연 로딩 시에는 애플리케이션에 필요한 데이터가 캐시에 로드
- 일부 사용 사례에서는 캐시 미스 비율이 높아질 수 있음
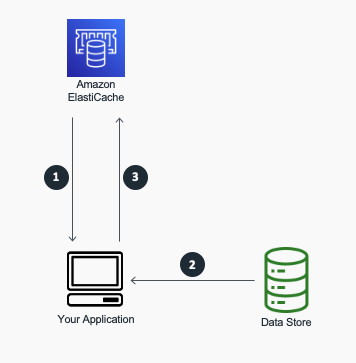
- 애플리케이션이 데이터베이스에서 데이터를 읽어야 하는 경우 먼저 캐시를 확인하여 데이터를 사용할 수 있는지 확인
- 데이터를 사용할 수 있는 경우( 캐시 적중 ) 캐시된 데이터가 반환되고 호출자에게 응답
- 데이터를 사용할 수 없는 경우( 캐시 미스 ) 데이터베이스에서 데이터를 쿼리하고, 다음 캐시는 데이터베이스에서 검색된 데이터로 채워지고 데이터는 호출자에게 반환
2. Write-Through(라이트 스루)
- 데이터베이스에 액세스할 때마다 수행
- 캐시 미스 감소 효과
- 성능이 개선되지만 애플리케이션에 필요하지 않을 수 있는 데이터용 추가 스토리지가 필요
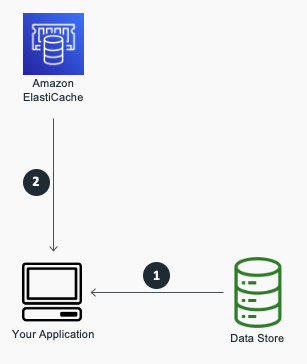
- 애플리케이션, 배치 또는 백엔드 프로세스는 기본 데이터베이스를 업데이트
- 그 직후 데이터는 캐시에서도 업데이트
캐시 관리:
| 캐시 유효성 | - TTL(Time To Live) 값을 각 애플리케이션 쓰기에 추가 - 데이터를 최신 상태로 유지 - 여분의 데이터로 인해 캐시가 가득차는 현상 방지 |
| 메모리 관리 | - 캐시메모리를 제거 정책에 따라 제거 - 제거 정책을 평가하는 데이터 특성: - 액세스 한지 가장 오래된 데이터 - 액세스 빈도가 가장 낮은 데이터 - TTL 세트와 TTL 값이 설정되어 있는 데이터 |
Amazon ElastiCache:
Amazon ElastiCache는 분산 인 메모리 데이터 스토어 또는 캐시 환경을 원활하게 설정, 관리 및 확장할 수 있는 웹서비스입니다.
이 서비스는 확장 가능하며 비용 효율적인 고성능 캐싱 솔루션을 제공합니다.
분산 캐시 환경 배포 및 관리와 관련된 복잡한 작업도 수행할 필요가 없습니다.
ElastiCache는 다음 인 메모리 엔진을 지원합니다:
1. Redis
2. Memcached
| Memcached | Redis | |
| 1밀리초 미만의 지연시간 | O | O |
| 수평 스케일링 | O | O |
| 다중 AZ 배포 | O | O |
| 다중 스레드 | O | |
| 고급 데이터 형식 | O | |
| 데이터 세트 정렬 및 순위 지정 | O | |
| 게시 및 구독기능 | O | |
| 백업 및 복원 | O | |
| 스냅샷 | O |
Amazon DynamoDB Accelerator(DAX):
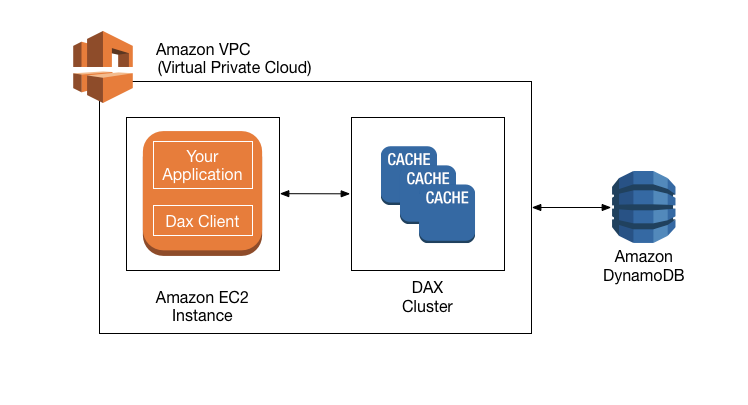
DynamoDB 응답 시간은 한 자릿수 밀리초 단위로 측정할 수 있습니다.
DynamoDB Accelerator(DAX)는 DynamoDB를 위한 완전 관리형 고가용성 캐시로, 마이크로초 응답 시간을 제공합니다.
Amazon VPC에 DAX 클러스터를 생성하여 캐시 된 데이터를 애플리케이션에 더 가깝게 저장할 수 있습니다.
5. 기존 데이터베이스를 AWS 클라우드로 마이그레이션
AWS Database Migration Service(DMS)를 사용하여 클라우드로 데이터베이스를 마이그레이션할 수 있습니다
AWS Database Migration Service(DMS):
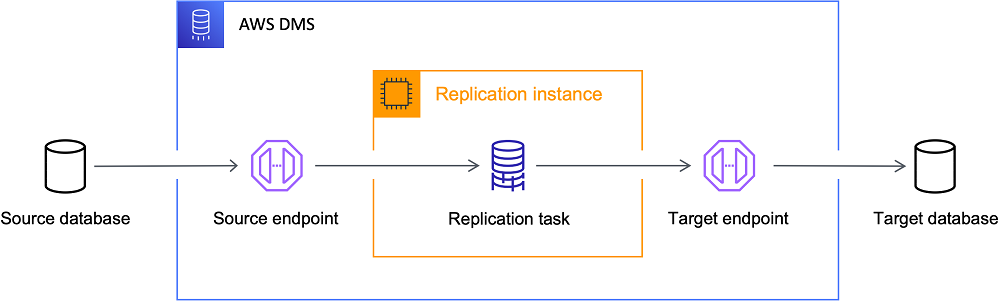
AWS DMS는 원본에서 AWS 클라우드의 대상 데이터베이스로 데이터를 복제합니다.
동종(동일한 엔진) 및 이종(서로 다른 엔진) 마이그레이션을 지원합니다.
두 개의 온프레미스 데이터베이스 간에는 마이그레이션할 수 없습니다(소스 또는 대상 데이터베이스가 Amazon RDS 또는 Amazon EC2에 있어야 합니다).
데이터베이스 뿐만 아니라 Amazon S3, AWS Snowball Edge 또는 다른 서비스를 가리킬 수 있습니다.
AWS Schema Conversion Tool(AWS SCT):
AWS SCT을 사용하면 이기종 데이터베이스를 예측 가능한 방식으로 마이그레이션할 수 있습니다.
소스 데이터베이스 스키마와 데이터베이스 코드 객체(보기, 저장된 프로시저, 함수 등)를 자동으로 평가하고 대상 데이터베이스와 호환되는 형식으로 변환합니다.
스키마 변환이 완료되면 내장된 데이터 마이그레이션 에이전트를 사용하여 다양한 데이터 웨어하우스에서 Amazon Redshift로 데이터를 효과적으로 마이그레이션합니다.
AWS SCT의 주요 이점:
- 스키마 분석, 권장 사항 및 변환을 대규모로 자동화하여 데이터베이스 마이그레이션을 간소화
- Oracle, SQL Server, PostgreSQL 및 MySQL과 같은 주요 데이터베이스 및 분석 서비스가 소스 및 대상 엔진으로 호환
- 수동으로 작업하는 시간 및 리소스 절약
Architecting on AWS 7.4.6 (KO): Student Guide 참고
'AWS > AWS Architecting' 카테고리의 다른 글
| [AWS Architecting]자동화 (0) | 2023.07.02 |
|---|---|
| [AWS Architecting]모니터링 및 크기 조정 (0) | 2023.07.02 |
| [AWS Architecting]스토리지 (0) | 2023.07.01 |
| [AWS Architecting]컴퓨팅 (0) | 2023.06.29 |
| [AWS Architecting]네트워킹 (0) | 2023.06.29 |