크롤링이란?
크롤링은 필요한 데이터가 있는 웹(Web)페이지의 구조를 분석하고 파악하여 긁어오는 행위입니다.
출처: https://modulabs.co.kr/blog/crawling-tips/.
데이터베이스에 테이블을 만드는 것 까진 좋았는데
테이블 값을 언제 다 넣고있냐... 하는 고민이 들 때가 있습니다.
만약 상업적인 목적이 아니라면 쇼핑 사이트에서 크롤링을 해서 데이터를 받아오면 편하게 데이터를 채울 수 있습니다.
이번 포스팅에서는 네이버 쇼핑의 남성 의류 상의 데이터를 크롤링해볼겁니다.
https://search.shopping.naver.com/search/category/100000393
네이버 쇼핑
네이버쇼핑 카테고리 검색 결과입니다
search.shopping.naver.com
1. Python
BeautifulSoup 모듈을 사용할겁니다.
pip install beautifulsoup4 명령어로 모듈 설치부터 해줍니다.

그리고 아래와 같이 python 코드를 작성합니다.
# python 파일
import requests
from bs4 import BeautifulSoup
res = requests.get('https://search.shopping.naver.com/search/category/100000393')
soup = BeautifulSoup(res.content, 'html.parser')
section = soup.find('div', id='content')
titles = section.find_all('a','basicList_link__JLQJf')
for title in titles:
print(title.get_text())
res는 크롤링 할 주소로, 위에 네이버 쇼핑 사이트 주소를 넣었습니다.
section은 해당 사이트에서 크롤링 할 정보의 html 태그 값입니다.
이게 무슨 뜻인지 chrome 개발자 모드로 확인해봅시다.
chrome에서 F12를 누르면 개발자 모드로 들어갈 수 있습니다.
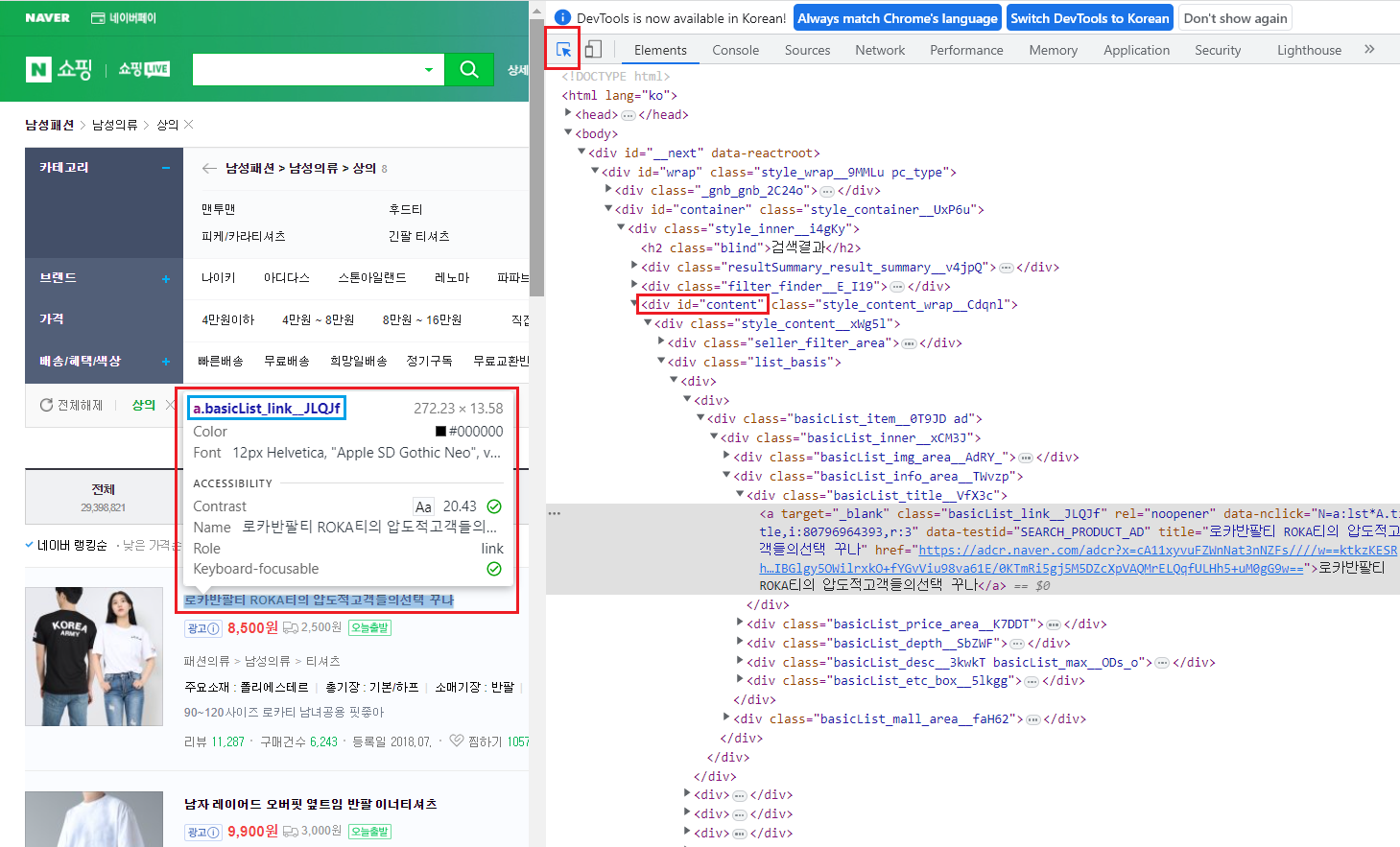
빨간 네모표시 안에 있는 파란색 화살표 기호를 누르고 상품명에 마우스를 올리면 해당 정보가 뜹니다.
section = soup.find('div', id='content') 코드는 div 태그이고 id가 content인 범위를 사용하겠다는 뜻입니다.
titles = section.find_all('a','basicList_link__JLQJf') 코드는 section 안에 있는 a 태그에 class가 basicList_link__JLQJf인 값을 크롤링해 오겠다는 뜻입니다.
그 외 코드는 따로 건드리지 않아도 됩니다.
한 번 돌려볼까요?

그런데 데이터가 빈약하네요.
한 페이지만 크롤링해와서 그렇습니다.
그럼 10페이지를 한 번에 받아올 수 있도록 코드를 바꿔볼까요?
# python 파일
import requests
from bs4 import BeautifulSoup
for page_num in range(10):
if page_num == 0:
res = requests.get('https://search.shopping.naver.com/search/category/100000393')
else:
res = requests.get('https://search.shopping.naver.com/search/category/100000393?catId=50000830%2050000831%2050000833&origQuery&pagingIndex=' + str(page_num + 1) + '&pagingSize=40&productSet=&query&sort=rel×tamp=&viewType=list')
soup = BeautifulSoup(res.content, 'html.parser')
data = soup.select('a.basicList_link__JLQJf')
for item in data:
print (item.get_text().strip())
if page_num == 0문은 0페이지는 기존 페이지
else문은 그 이상을 받아오기 위한 코드입니다.
주소를 왜 저렇게 지정했냐면,

위 사진을 보면 페이지가 넘어갈수록 pagingindex만 바뀌는 것을 알 수 있습니다.
그래서 for 문을 돌릴 때 pagingindex번호만 바꿔주면 여러 페이지를 한 번에 크롤링 해올 수 있습니다.
확인해볼까요?

아까보다 훨씬 낫습니다.
이제 같은 방법으로 금액도 가져와봅시다.
# python 파일
for page_num in range(10):
if page_num == 0:
res = requests.get('https://search.shopping.naver.com/search/category/100000393')
else:
res = requests.get('https://search.shopping.naver.com/search/category/100000393?catId=50000830%2050000831%2050000833&origQuery&pagingIndex=' + str(page_num + 1) + '&pagingSize=40&productSet=&query&sort=rel×tamp=&viewType=list')
soup = BeautifulSoup(res.content, 'html.parser')
data = soup.select('span.price_num__S2p_v')
for item in data:
print (item.get_text().strip())
data = soup.select('span.price_num__S2p_v') 코드는

여기서 받아왔습니다.
위 과정과 동일하니 이 부분은 어렵지 않을겁니다.
마지막으로 금액도 돌려보고 마치겠습니다.

참고 사이트: https://www.inflearn.com/course/python-crawling-basic/dashboard
'window 환경에서 개발하기 > 기타' 카테고리의 다른 글
| VirtualBox에서 Windows10 설치하기(productkey 에러 해결) (0) | 2024.11.20 |
|---|---|
| Window update: 윈도우 업데이트 끄기 (0) | 2023.05.11 |
| SQLite Browser 설치 없이 SQLite 파일 열기 (0) | 2023.05.11 |
| 윈도우 cmd에서 리눅스 명령어 사용하는 방법(WSL 설치) (1) | 2023.04.26 |